はじめに
日本語BERT学習済みモデルを使った日本語の文章ベクトル作成をしてみました。今回は環境構築無しでGoogle Colaboratoryを使ってGoogleアカウントがあればクラウドで手軽にできる方法で文章ベクトルを求めるプログラムを動かしてみたいと思います。機械学習を勉強されている方や、それを自然言語に活用しようと思っていらっしゃる方向けの技術情報になれば幸いです。
BERTとは何か?
BERTとは、Bidirectional Encoder Representations from Transformers の略で、 「Transformerによる双方向のエンコード表現」と訳され、2018年10月にGoogleのJacob Devlinらの論文で発表された自然言語処理モデルです。翻訳、文書分類、質問応答など自然言語処理の仕事の分野のことを「(自然言語処理)タスク」と言いますが、BERTは、多様なタスクにおいて当時の最高スコアを叩き出しました。
https://ledge.ai/bert/
AI関係の情報メディアから引用させていただきましたが、すごく簡単に言ってしまうと、BERTは自然言語処理向けの機械学習モデルです。特徴としては高い精度で計算できることやベースとなる学習済みのモデルがあれば追加データを学習させることで特定用途向けにチューニングができることのようです。このモデルを使うと、文章を入力して翻訳をしたり、質問に対して適切な回答文を出力したりなどのアプリケーションを作ることができます。(もちろん、そのためには入力と出力の処理と、大量のデータ学習が必要ですが…)
文章ベクトルとはなにか?
文章ベクトルとは自然言語の文章を数値化したものになります。ベクトルというのは高校の数学で出てくる数字の組のことですが、この数字の組を使って文章の特徴を表現したものが文章ベクトルになります。例えば「今日の東京は雪になるでしょう」を、今回紹介する手法で文章ベクトルにすると、以下のような768個の数字の並び(すなわち768次元)になります。
-1.68849438e-01, 1.37653828e+00, 1.23953186e-01, -6.89988434e-02, -7.17968196e-02, -2.02147782e-01, ... -1.08952574e-01, -3.49897653e-01, 3.30110103e-01
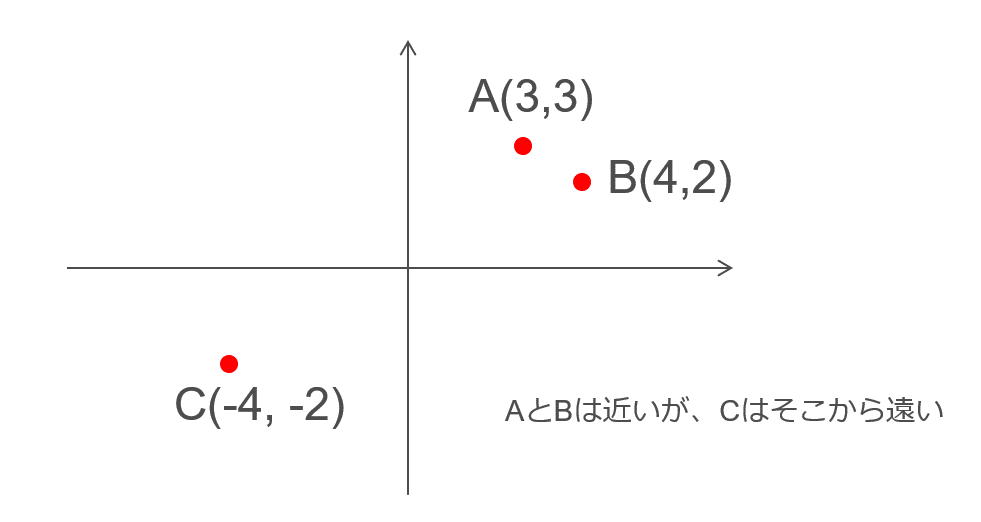
ぱっと見て意味が分からない数字の羅列ですね。これが一体何に使えるのか?ですが、これは文章の特徴を表現しているので、似たような文章は近い文章ベクトルになります。ここで近いというのはベクトルの距離のことで、例えば下図のような2次元数値ベクトルはグラフ上に点を打つとAとBのベクトルは近い、Cは遠いと分かります。次元が多くても同じように距離を計算することができ、この距離が近いものは似た意味の文章であるなど、文の意味理解に利用することができるようになります。
また、機械学習は入力が数値ベクトルである必要があるため、この手法で求めた文章ベクトルを他の機械学習モデルの入力に使うなどしてさまざまなアプリケーションに応用ができます。
BERTのモデルを準備する
非常に簡単でしたがBERTと文章ベクトル説明はこれくらいにして、早速、文章ベクトルを求めるプログラムを動かしてみましょう。
先に説明したように、BERTは機械学習のモデルであり、モデルを作るには大量のデータ(大量の日本語の文章)の学習が必要になります。これをゼロから作るのはデータの収集、加工、学習など、どれも時間のかかる非常に大変な作業になります。
しかし、ありがたいことに日本語のWikipediaの大量の文章で学習済みモデルを作り公開してくださっている方がいらっしゃいます。こちらのモデルを利用することで上記の作業をしないでもBERTで日本語の文章を処理するプログラムを作ることができます。(感謝です)
BERT with SentencePiece を日本語 Wikipedia で学習してモデルを公開しました
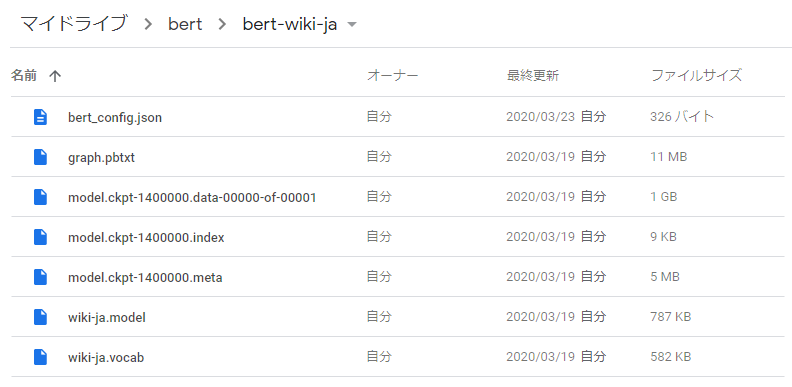
公開されているのはKeras BERTで使える学習済みモデルです。上記リンク先のページにGoogle driveのリンクがあるので、以下のファイルをダウンロードしてください。一番サイズが大きいbz2ファイルは使わないので不要です。
- graph.pbtxt
- model.ckpt-1400000.data-00000-of-00001
- model.ckpt-1400000.index
- model.ckpt-1400000.meta
- wiki-ja.model
- wiki-ja.vocab
ファイルをダウンロードしたら自分のGoogle Driveのマイドライブの下にbertフォルダを作成、その中にbert-wiki-jaフォルダを作成して上記ファイルをすべてアップロードします。Google Driveを使っていない方は準備してくださいね。
さらに、こちらから以下ファイルをダウンロードして、同様にbert-wiki-jaフォルダにアップロードします。このファイルは先にアップロードしたモデルファイルを使うのに必要な設定値が記載されているファイルになります。
最終的にGoogle Driveに以下のファイルがそろっていれば大丈夫です。
文章ベクトルを作る
こちらからプログラム本体である以下のファイルをダウンロードしてGoogle Driveの任意のフォルダにアップロードします。(ファイルをクリックするとバイナリが表示されますがメニューからダウンロードを選んでいただければ大丈夫です)
Google Colaboratoryが使えるようにGoogle Driveに設定をして、このファイルをGoogle Colaboratoryで開きます。

開いたらメニューのRuntime→Run all を選択(または[Ctrl]+[F9])して実行すると、コードが順に走ります。
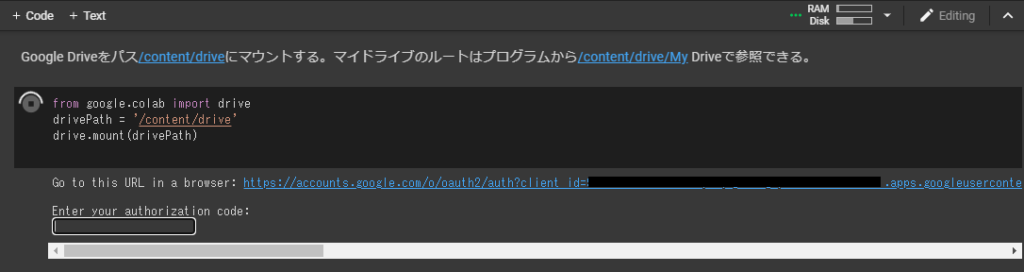
途中一か所「Google Driveをパス/content/driveにマウントする」という部分で以下図のように表示されコードの入力待ちになります。Google Driveのファイルを参照するために認証を通す必要があるため、”Go to this URL in a browser”で表示されたリンクをクリックし、画面の指示に従ってGoogle Driveへのアクセス許可を与え、最後に表示されたコードを、“Enter your authorization code” に入れると先に進みます。
最後のコードセルの、textに設定された文章が文章ベクトルを作る対象の文章です。

ここを実行すると以下のような768次元の文章ベクトルが画面に表示されます。
array([[ -1.68849438e-01, 1.37653828e+00, 1.23953186e-01, -6.89988434e-02, -7.17968196e-02, -2.02147782e-01, -2.96043977e-02, 5.82927316e-02, 4.59994912e-01, ... -3.57352644e-01, -7.30618760e-02, -2.79066086e-01, -1.08952574e-01, -3.49897653e-01, 3.30110103e-01]], dtype=float32)
うまくうごきましたでしょうか?
textを書き換えて、このコードセルを再度実行すると文章ベクトルが再計算され出力されます。
日本語の文章を自由にベクトル化できると何に使おうか楽しみが広がりますよね。
おつかれさまでした!
コード説明
ここからはプログラムの中身に興味がある人向けの内容になります。今回動かしたコードbert_sentencevector_test1.ipynbの説明をかいつまんでしていきたいと思います。
最初のコードブロックでは使用するライブラリをインストールしています。sentencepieceは自然言語処理のライブラリ、keras_bertはBERTのライブラリです。今回利用した学習済みモデルは学習データの文章をSentence Pieceで単語分割と単語のコード化をしてKeras BERTで学習して作成されています。このためプログラムでもこれらのライブラリを使用します。
Google Colaboratoryは開くとPythonと機械学習のライブラリがプリインストールされた仮想マシンが起動しますが、これらのライブラリはインストールされていないので、pipコマンドでインストールをしています。pipコマンドの前についている「!」はOSコマンドを動かすためのしるしです。
!pip install sentencepiece
!pip install keras_bert次のコードブロックではGoogle Driveからファイルを読み込む準備をします。この処理でGoogle Driveをパス/content/driveにマウントします。認証を行うとGoogle Driveのマイドライブのルートはプログラムから/content/drive/My Driveで参照できるようになります。
drivePath = '/content/drive'
drive.mount(drivePath)次のコードブロックでは、関数load_trained_model_from_checkpointで、マウントしたGoogle Drive上に配置されているBERTの学習済みモデルを読み込んでいます。この読み込みは数分かかります。そのあと、関数summaryでモデルの内容を表示しています。出力された内容から入力が512次元、出力が768次元の機械学習モデルであることが分かります。
from keras_bert import load_trained_model_from_checkpoint
bertPath = drivePath + '/My Drive/bert/'
config_path = bertPath + 'bert-wiki-ja/bert_config.json'
checkpoint_path = bertPath + 'bert-wiki-ja/model.ckpt-1400000'
bert = load_trained_model_from_checkpoint(config_path, checkpoint_path)
bert.summary()次のコードブロックではSentence PieceにBERTの学習済みモデル構築に使用した言語のモデルを読み込んでいます。
spp = spm.SentencePieceProcessor()
spp.Load(bertPath + 'bert-wiki-ja/wiki-ja.model')次のコードブロックで、引数のテキストから文章ベクトルを求めて返す関数text2vectorを定義しています。この関数ではまずテキストをSentence Pieceでトークンに分割しコード化をします。そのトークン列にの先頭に先頭記号[CLS]、最後に最終記号[SEP]を付与してBERTへの512次元の入力ベクトルを作成しています。そのベクトルを関数bert.predictに渡し768次元の文章ベクトルを作成しています。
def text2vector(text):
maxlen = 512 # from BERT config
common_seg_input = np.zeros((1, maxlen), dtype = np.float32)
matrix = np.zeros((1, maxlen), dtype = np.float32)
token = [w for w in spp.encode_as_pieces(text.replace(" ", ""))]
if token and len(token) <= maxlen:
tokens = []
tokens.append('[CLS]')
tokens.extend(token)
tokens.append('[SEP]')
for t, token in enumerate(tokens):
try:
matrix[0, t] = spp.piece_to_id(token)
except:
print(token+"is unknown")
matrix[0, t] = spp.piece_to_id('<unk>')
return bert.predict([matrix, common_seg_input])[:,0] # embedding of [CLS]一番最後のコードブロックで関数text2vectorに文章を渡して文章ベクトルを計算しています。
text= '今日の東京は雪になるでしょう'
text2vector(text)コードはこれで終了になります。
おわりに
本記事がAI・機械学習(Machine Learning)を学ぶ人の参考になれば幸いです。
当社では機械学習とオントロジー技術によるハイブリッド会話AIプラットフォーム「ENOKI」を開発しています。自然言語処理を応用した音声会話アプリケーションやチャットボットでの顧客接点にご利用いただける製品です。詳細はぜひこちらのページをご覧ください。
参考文献
本記事はQiitaに投稿した以下記事に加筆・修正をしたものです。
元記事はこちらの参考文献を参考にさせていただきました。貴重な情報を公開していただきどうも有難うございます。
