はじめに
前回の記事「fastTextを使用した文章ベクトル作成」では日本語のfastText学習済みモデルを使い、日本語の文章ベクトル作成についてご紹介しました。文章ベクトルとは自然言語の文章の特徴を数値化したもので、似た文章は近い文章ベクトルになります。「BERTによる文章ベクトルを視覚化する」の記事ではBERTで作った文章ベクトルをグラフにプロットして近さを実感しましたが、今回はfastTextの文章ベクトルを視覚化してみたいと思います。今回もGoogle Colaboratoryを使ってプログラムを動かしてみます。
fastTextのモデルを準備する
まずはfastTextのモデルの準備が必要となります。前回記事で紹介した文章ベクトルを求めるプログラムをすでに動かしていれば、同じモデルを使用するので準備は不要です。まだ準備をしていない方は前回記事「fastTextを使用した文章ベクトル作成」を参照して準備を進めてください。
文章ベクトルの視覚化
前回紹介した方法で作ったfastTextの文章ベクトルは300次元になります。「BERTによる文章ベクトルを視覚化する」の記事ではBERTで作った768次元の文章ベクトルを、t-SNEという高次元ベクトルの次元圧縮をするツールで2次元にして平面上にプロットしました。今回も同じくt-SNEを使って300次元の文章ベクトルを2次元にして視覚化することにします。
では、始めましょう。こちらからプログラム本体である以下のファイルをダウンロードしてGoogle Driveの任意の場所にアップロードします。
似た文章のデータとしてこちらから以下ファイルをダウンロードして、Google Driveのマイドライブ直下のfasttextフォルダに保存します。
このファイルはcategoryとinputの列を持つ書式となっており、類似の文章にはcategoryに同じ番号が振られています。飲食店によくある質問文9個のcategoryに分け合計80文を使用します。こちらはBERTの視覚化の時と同じ文章データとなります。同じ文章でそれぞれのアルゴリズムでどう違いが出るか、最後に比べてみたいと思います。
category,input
1,お弁当の配達はお願いできますか?
1,弁当を配達してもらえる?
1,お弁当はやってますか
… 省略 …
2,ペットを連れて利用できますか?
2,ペット同伴してもいいですか
2,ペットは一緒に入れる
… 省略 …
先にアップロードしたプログラム本体をGoogle Colaboratoryで開きます。開いたらメニューのRuntime→Run all ([Ctrl]+[F9])で実行すると、コードが順に走ります。
途中一か所「Google Driveをパス/content/driveにマウントする」という部分で以下のように表示されます。Google Driveのファイルを参照するために認証を通す必要があるため、”Go to this URL in a browser”で表示されたリンクをクリックし、画面の指示に従ってGoogle Driveへのアクセス許可を与え、最後に表示されたコードを、“Enter your authorization code” に入れると先に進みます。
最後のコードブロックが実行されると、input1.csvの質問文を文章ベクトルに変換、それを2次元に変換しcategoryで色分けして平面上にプロットします。正常に実行できると最後に下図のようなプロットが表示されると思います。
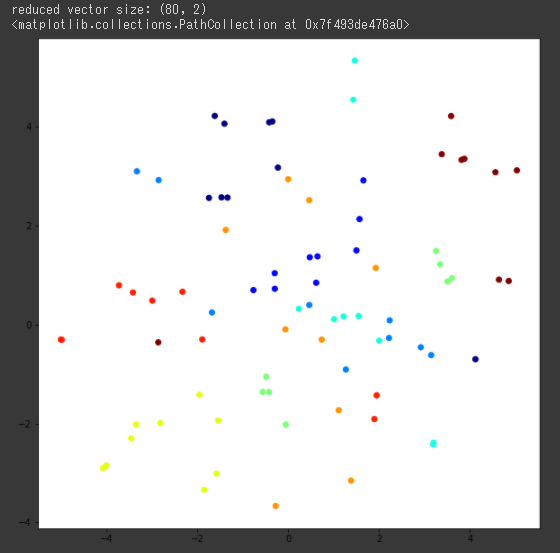
色が同じ点はinput1.csv中で同じcategoryを持つ文章、すなわち類似の文章を示しています。同じ色が近い場所にあれば、類似の文章はベクトル的に近い場所にあることがいえます。
BERTとfastTextの文章ベクトルプロット比較
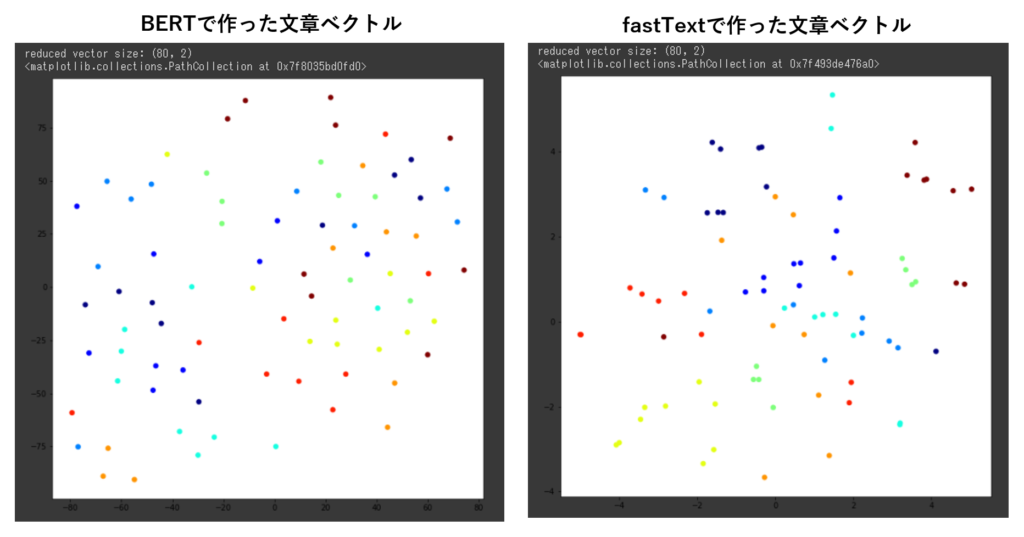
BERTとfastTextによる文章ベクトルを作りましたので並べて比べてみましょう。それがこちらの図になります。
見た時の感覚的な部分もあると思うのですが、なんとなくfastTextのほうが、同じ意味の文章のベクトルはまとまっているようにも見えました。今回の文章のデータセットではたまたまこのような結果になりましたが、他のデータセットではどうなるか?大変興味深いところではあります。実際に試してみた方いらっしゃいましたら報告いただけると嬉しいです。
コード説明
ここからはプログラムの中身に興味がある人向けの内容になります。今回動かしたコードfasttext_sentencevector_test2.ipynbの説明をかいつまんでしていきたいと思います。
引数のテキストから文章ベクトルを求めて返す関数text2vextorの定義までは前回の記事と同じコードとなりますので説明は省略します。
今回はCSVファイルから質問文を順に読み込んで関数text2vectorで文章ベクトルを計算しています。それを実施している部分が以下のコードブロックとなります。各文の文章ベクトルは変数svに格納しています。すべての文章ベクトルの計算が終わるとsvは80文の300次元のベクトルが格納された (80, 300)の行列となっています。
# 質問リストのCSVを読み込む。
# 質問種別,質問文、の形式になっている。
# index_col=Falseを付けないと1列目の数字を正しく読まない
features_df = pd.read_csv(bertPath + '/My Drive/fasttext/input1.csv',
encoding="cp932", index_col=False, dtype=str)
categories = features_df['category'].astype('category').cat.codes.values.tolist()
catnum = max(categories)+1 print('corpus size:',features_df['input'].size)
print('categories:',catnum) # 質問リストの先頭を表示 print(features_df.head())
# すべての質問文に対して文章ベクトルを求める
sv = np.empty((0,300), np.float32)
for sentence in features_df['input']:
_sv = text2vector(sentence)
if _sv is not None:
sv = np.append(sv, _sv, axis=0)
print('vector size:',sv.shape)最後のコードブロックでsklearnの関数TSNE でt-SNEによる300次元から2次元への次元圧縮を行っています。変数 sv に格納されている80文、300次元の文章ベクトル、(80, 300)の行列は、関数TSNEを通すとsv_reduced に(80, 2)の行列で格納されます。これを質問種別ごとに色分けしてプロットしています。matplotの関数cm.jetは0~1の間の数値を色分けするのに使えますので0~1の範囲をカテゴリの数に等分して色分けするようにしました。
# 768次元→2次元に圧縮する
sv_reduced = TSNE(n_components=2, random_state=0).fit_transform(sv)
print('reduced vector size:',sv_reduced.shape)
# 質問種別(category)ごとに色分けして表示
colors = [cm.jet(i/(catnum-1)) for i in categories]
plt.figure(figsize=(10, 10))
plt.scatter(sv_reduced[:, 0], sv_reduced[:, 1], c=colors)コードはこれで終了になります。
おわりに
本記事がAI・機械学習(Machine Learning)を学ぶ人の参考になれば幸いです。
当社では機械学習とオントロジー技術によるハイブリッド会話AIプラットフォーム「ENOKI」を開発しています。自然言語処理を応用した音声会話アプリケーションやチャットボットでの顧客接点にご利用いただける製品です。詳細はぜひこちらのページをご覧ください。
参考文献
本記事はQiitaに投稿した以下記事に加筆・修正をしたものです。
t-SNEについて説明やアルゴリズムの参考資料です。
