今、巷ではChatGPTの話題で溢れています。日本では2023年6月現在、ChatGPTの認知度は68.8%、利用率は15.4%を増加傾向にありますが、みなさんはChatGPTを「質問すれば何でも正解を答えてくれる。これがAIの本来の姿だ!」と思われている人も多いのではないでしょうか?この記事ではこういった意見について少し深掘りをしていきたいと思います。
まず、ChatGPTは「生成AI」の1つです。GPTは「Generative Pre-trained Transformer」の略であり、大量のデータを基に学習する文章生成言語モデルのことです。そもそも生成AIはさまざまなコンテンツを生成できるAIのことで、文章生成に特化したものがChatGPTになります。
では、どのように文章を生成しているのでしょう。
GPTの実体はTransformerと呼ばれるニューラルネットワークモデルで表現されます。内部はブラックボックスとなっているので詳細は不明ですが、おおよそ以下のようなイメージになると推測されます。
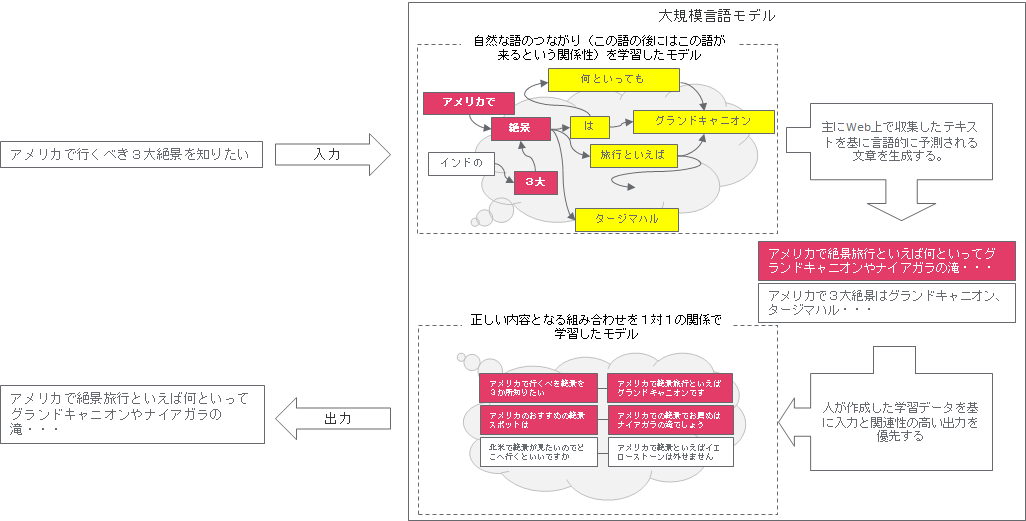
また、GPTモデルにはいくつかありますが、GPT3.5モデルが学習しているデータ量は45TB(テラバイト)です。45TBというと非常に膨大なデータ量だと感じますね。一方で総務省から2020年に出ている情報通信白書には世界の公開データ量は59ZB(ゼタバイト)と記載があります。ここから比較するとGPT3.5モデルの学習量は世界の公開データのわずか0.000000076%でしかありません。ChatGPTがいくら文章生成に特化しているといっても、このデータ量から生成される文章には限りがあるということですね。
他にも、ChatGPTから正解を得るためには、適切な応答を生成するために与えるテキスト情報、すなわち「プロンプト」が必要になります。プロンプトには大きく分けて以下の2種類があると考えてよいです。
- 背景情報を指定するプロンプト
- 表現方法を指定するプロンプト
これらのプロンプトがどのように作用するか、詳しく説明します。
背景情報を指定するプロンプト
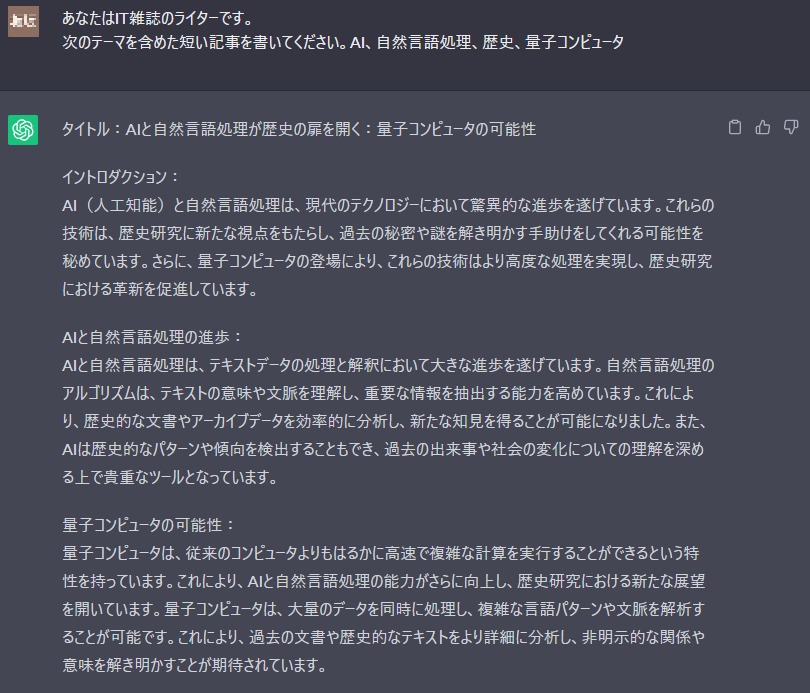
より精度の高い応答を得るために、「どういう背景情報を基にするのか」を指定することが必要です。例を以下に示します。
成功例:記事が作成された
失敗例:アジェンダしか作成されなかった
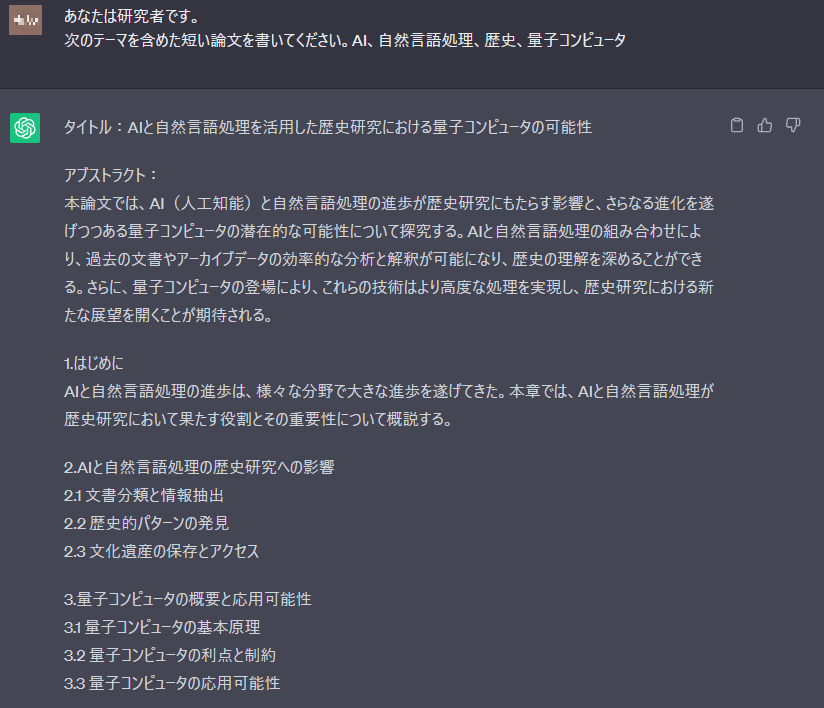
それぞれ入力したプロンプトの日本語構成は同じですが、指示通り生成されて出力されるものもあれば、指示通り生成できず意図通りの出力がなされないものもあります。このようにどのようなプロンプトを入力すれば得たい応答が得られるかは、OpenAIのGPTモデルに依存することが多く、モデル更新によっても変化することもあることから応答を完全に制御することは不可能に近いです。
表現方法を指定するプロンプト
自分が必要な応答を得るために、「どんな説明にするのか」という表現を指定することが必要です。上記の例のように「あなたはIT雑誌のライターです。」といった役割を設定することも有効です。他にも
- 新入社員でもわかるように説明してください。
- 小学生でもわかるように説明してください。
- 学校の先生のように教えてください。
など必要な応答に応じたプロンプトの指定が必要です。ただ、背景情報を指定するプロンプト同様、OpenAIのGPTモデルに依存することが多く、モデル更新によっても変化することもあることから応答を完全に制御することは不可能に近いです。
まとめ
冒頭に、ChatGPTは「質問すれば何でも正解を答えてくれる。これがAIの本来の姿だ!」と思われていた方、
- 学習済みのデータ量は世界で公開されているデータの0.000000076%に過ぎない。
- プロンプトは完全に制御することは難しい。
といった点から、決してそんなことはないこいうことご理解いただけたかと思います。もちろんGPT4モデルなどは更に精度が上がっていますが、上記の問題がつきまとうことには変わりありません。
後編では、企業データを教師データにしてChatGPTを利用する上での活用方法やリスクについて記事を書きたいと思います。
