はじめに
BERTを使用した文章ベクトル作成の記事では、日本語BERT学習済みモデルを使った日本語の文章ベクトル作成をしてみました。文章ベクトルを作ることで、文章の分類や、機械学習アプリケーションへの入力として使うなど、色々な自然言語処理に応用することができます。文章ベクトルを作るには自然言語処理モデルを使いますが、モデルには色々な種類がありBERTだけでなく、その進化系のALBERTや、XLNetなど新しいモデルが提案され精度向上を謳っています。
今回はBERT以外のモデルでの文章ベクトル作成を試してみたいと思います。今回使うモデルは、Facebookで開発されたfastTextです。fastTextを自然言語に活用しようと思っていらっしゃる方向けの技術情報になれば幸いです。
fastTextとは何か?
Word2Vecを考案したトマス・ミコロフが、GoogleからFacebookの人工知能研究所「Facebook AI Research」に移籍し、Word2Vecを発展させる形で生み出したのがfastTextです。その特徴は、圧倒的な単語学習スピードの速さにあります。Facebookは、標準的なCPUを用いた場合でも、10分以内で10億語を学習でき、5分以内で50万もの文を30万のカテゴリーに分類できると公式発表で述べています。
https://ledge.ai/word2vec/
AI関係の情報メディアから引用させていただきました。簡単に言ってしまうと単語を意味に応じた数値ベクトルにすることができる自然言語処理のモデルになります。単語間の相関関係がベクトルの関係に現れるので近い用法の単語については類似したベクトルが得られます
ここまで説明すると、「あれ、文章ベクトルでなくて、単語なの?」と思われたあなたは鋭いです。fastTextは文章のベクトルでなく、文章を構成する個々の単語のベクトルを計算できる自然言語のモデルです。
fastTextで文章ベクトルをどう作るか
方法はともかく文章ベクトル作りを試したい方、ここは読み飛ばして次の節に行っても大丈夫です。
先に紹介したようにfastTextは単語の数値ベクトル表現を得るロジックです。この単語ベクトルを使って文章のベクトルを得るための方法はいろいろ考案されているようですが、文章に含まれるすべての単語のベクトルを求めてその平均を文章ベクトルとする方法を今回は使うことにします。この方法だと語順の情報は消えてしまうので係り受けや前後関係が文の意味に影響を与えるような長い文章、複雑な文章には適さないかと思われます。逆に倒置など語順が変わることが多い会話文や短い質問文のようなものでは十分利用でき、計算方法単純なので高速というメリットがあるかと思います。
fastTextのモデルを準備する
BERTの時と同様fastTextも学習済みモデルが必要となります。これをゼロから作ると大変な作業ですが、学習済みモデルを公開してくださっている方がいらっしゃいますので、こちらを使用して文章ベクトルを作成することにします。
こちらのページにDownload Word Vectorsのリンクがあるのでそちらからファイルをダウンロードしてください。2種類の学習済みモデルが公開されています。fastTextは単語のモデルになるので日本語のモデルでは元となる単語辞書が必要になりますがその種類の違いになります。無印のほうはMecabの標準辞書をベースとしたモデル、NEologd版はWikipediaをもととした辞書NEologdを使用したモデルです。選んだモデルにより文章ベクトルを求めるプログラムも合わせたものとする必要があります。辞書ごとに特徴がありますのでどちらを使用するかは実現したい自然言語処理の対象により選びますが、今回は文章ベクトルを作ることが目的なので、実施しやすい標準辞書のほうを使うことにしましょう。無印のほうをダウンロードします。
前回の記事同様、Google Colaboratoryを使いやってみたいと思います。ダウンロードしたvector.zipを展開してmodel.vecを取り出します。自分のGoogle Driveのマイドライブの下にfasttextフォルダを作成、その中にvectorフォルダを作成しmodel.vecをアップロードします。
最終的にGoogle Driveが下図の状態になっていれば大丈夫です。

文章ベクトルを作る
こちらからプログラム本体である以下のipynbファイルをダウンロードしてGoogle Driveの任意の場所にアップロードします。
Google Colaboratoryが使えるようにGoogle Driveに設定をして、このファイルをGoogle Colaboratoryで開きます。
開いたらメニューのRuntime→Run all を選択(または[Ctrl]+[F9])して実行すると、コードが順に走ります。
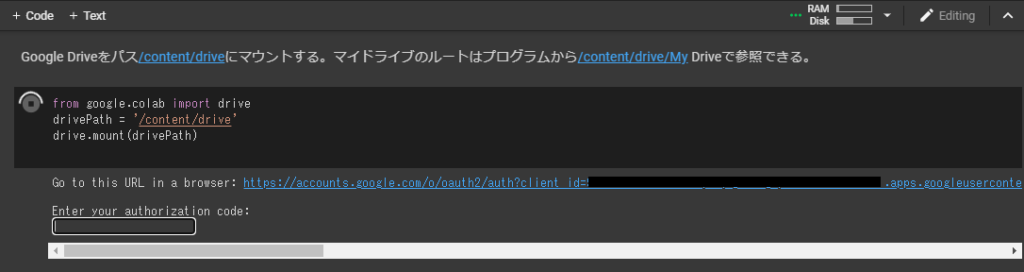
途中一か所「Google Driveをパス/content/driveにマウントする」という部分で以下図のように表示されコードの入力待ちになります。Google Driveのファイルを参照するために認証を通す必要があるため、”Go to this URL in a browser”で表示されたリンクをクリックし、画面の指示に従ってGoogle Driveへのアクセス許可を与え、最後に表示されたコードを、“Enter your authorization code” のところに入れると先に進みます。
最後のコードセルの、textに設定された文章が文章ベクトルを作る対象の文章です。

ここを実行すると以下のように300次元の文章ベクトルが画面に表示されます。
[[ 0.1202 -0.01985181 -0.03682778 0.09241433 0.06526966 -0.03810288
0.002114 0.031315 -0.07302511 0.05999633 0.12339155 0.036735
-0.01310033 0.00162244 -0.1747051 0.0203813 -0.07293266 -0.16425289
…
-0.113902 0.07032856 0.00790416 -0.05663266 -0.00517633 0.0051248
-0.04521288 -0.13712189 -0.17047666 -0.01394678 0.03347553 0.09704111
-0.04956407 -0.10511766 -0.06996578 -0.016097 -0.07823177 -0.06531233]]
textを書き換えて、このコードセルを再度実行すると文章ベクトルが再計算され出力されます。できるだけ簡単に最短手順で文章ベクトルを作る方法をご紹介しましたが、うまくいかなかったなどあればコメントください。BERTもいいですがfastTextはモデルのサイズも小さく軽いのがとてもいいですね。
おつかれさまでした!
コード説明
ここからはプログラムの中身に興味がある人向けの内容になります。今回動かしたコードfasttext_sentencevector_test1.ipynbの説明をかいつまんでしていきたいと思います。
最初のコードブロックでは使用するライブラリをインストールしています。fastTextは単語のベクトルを求めるモデルであるため、文章ベクトルを作るには文章を単語に分割する必要があります。文の単語分割のためにmecabを使用します。(先に説明したように今回使用したfastTextのモデルも同じmecabベースの単語を使って作られています) mecabはpythonとは別のプログラムでありpipコマンドではGoogle Colaboratoryにインストールできないのでapitudeコマンドを使えるようにしてからmecabをインストールしています。また、pythonでmecabを使うためのライブラリmecab-python3もインストールしていますが、試したところ最新版では動かないようでしたのでバージョンを指定して古いものを使っています。また、fastTextのモデルを動かすためにgensimが必要になりますので、こちらもpipコマンドでインストールしています。
!apt install aptitude swig
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.996.5
!pip install gensim次のコードブロックではGoogle Driveからファイルを読み込む準備をします。この処理でGoogle Driveをパス/content/driveにマウントします。認証を行うとGoogle Driveのマイドライブのルートはプログラムから/content/drive/My Driveで参照できるようになります。このあたりは前回記事と同じです。
drivePath = '/content/drive'
drive.mount(drivePath)次のコードブロックではmecabを準備します。
# mecab準備
m=MeCab.Tagger('-Owakati')次のコードブロックでは、gensimを使い、関数load_word2vec_format で、マウントしたGoogle Drive上に配置されているfastTextの学習済みモデルを読み込んでいます。読み込みには1~2分かかります。
# モデルのパス
modelPath = drivePath + "/My Drive/fasttext/vector/model.vec"
# モデルのロード
model = gensim.models.KeyedVectors.load_word2vec_format(modelPath, binary=False)次のコードブロックで、引数のテキストから文章ベクトルを求めて返す関数text2vectorを定義しています。入力テキストをmecabで単語に分割し、単語ごとのベクトルを関数model [w]で求めています。単語の文章ベクトルは300次元となります。最後にすべての単語のベクトルの平均を関数np.averageで計算し、300次元の文章ベクトルを作成して返しています。
def text2vector(text):
_sv = np.empty((0,300), np.float32)
for w in m.parse(sentence).split():
try:
wv = model[w]
_sv = np.append(_sv, np.array([wv]), axis=0)
except KeyError:
if w not in unknowns:
unknowns.append(w)
if _sv.shape[0]>0:
return np.array([np.average(_sv, axis = 0)])
else:
print('Ignore sentence', sentence)
return None一番最後のコードブロックで関数text2vectorに文章を渡して文章ベクトルを計算しています。
text= '今日の東京は雪になるでしょう'
text2vector(text)コードはこれで終了になります。
おわりに
本記事がAI・機械学習(Machine Learning)を学ぶ人の参考になれば幸いです。
当社では機械学習とオントロジー技術によるハイブリッド会話AIプラットフォーム「ENOKI」を開発しています。自然言語処理を応用した音声会話アプリケーションやチャットボットでの顧客接点にご利用いただける製品です。詳細はぜひこちらのページをご覧ください。
参考文献
本記事はQiitaに投稿した以下記事に加筆・修正をしたものです。
元記事はこちらの参考文献を参考にさせていただきました。貴重なモデルを公開していただきどうも有難うございます。
またmecabをGoogle Colaboratoryで動かすための方法はこちらを参考にさせていただきました。
